
[Not] A New Theory of Language

I hadn’t initially intended to explore language in my latest paper, its core idea was to describe conscious thought as a physical process—the brain represents, just as lungs breathe and the heart beats, it is their nature, it is what they do. However, this exploration led me to consider how our neurocomputational abilities emerge, which ultimately prompted me to further develop my framework to connect computational skills with the 4E cognitive approach, and it was this that allowed me to explain the emergence of linguistic abilities within a broader neural context. All in all, my paper ended up offering a new perspective on what language is, at least in part.
Two important points need to be made though: First, my conjecture about the origins of linguistic cognition does not require my entire framework to be viewed as a new theory of language. Similar conclusions could be reached through various other approaches, I simply happened to have an ideal framework that “gets there”, as it is indeed an effective model to illustrate multiscale emergence of higher-order cognitive phenomena. However, an intriguing feature of the framework is that, while it wasn’t essential to my conjecture, it allowed me to theorize about the cognitive origins of language in a way that aligns with existing theories—providing a foundation rather than creating conflicts or ideological divides, which is a powerful undertaking.
Second, this is not a new theory of language. Rather, it offers a first-principles explanation of existing theories, providing a hybrid, physics-based mechanism for the emergence of linguistic competence—a foundational layer, not a competing or opposing theory. Put another way, this framework is about moment 0 to 1, not 1 to 2.
In this post, I will elaborate on this novel proposition, detaching it from the main paper and expanding the discussion to AI and large language models (LLMs), positioning this framework within the broader industry context.
1. How My Framework Understands Language
For centuries, the nature of language has been debated as either an innate faculty or a learned skill, a system of symbols or a social tool. Some have argued that language is innate, a hardwired feature of the human mind (Chomsky, Fodor, Plato, Descartes) while others have proposed that language is learned through experience and interaction (Locke, Piaget, Krashen). Yet, despite the sophistication of these theories, what has been missing is a first-principles, physics-grounded account of how linguistic abilities emerge at all.
My framework provides A method to describe linguistic abilities as a foundational, thermodynamically grounded theory of cognition, where language is not an isolated module but an emergent property of recursive, self-organizing attractor states in neural state-space, rooted in the physics of neurocomputational skills. Through the interplay of Markov blankets, attractor dynamics, and computational primitives, I demonstrate how linguistic capabilities naturally arise—not as static, pre-specified structures, but as the result of the brain’s fundamental tendency to minimize energy and stabilize thought patterns over time. It is a perspective that bridges the chasm between innate structure and learned behavior, offering an unified explanation for how language emerges from the interplay of neurons, bodies, and environments.
In the table above, blue is for hybrid, green is for innate language theories, orange for learned theories and red for structural and/or functional theories. Under any of these, the present framework either explains how structures and context emerge from or are influenced by attractors/computational primitives (e.g., it provides a mechanistic basis for Pinker’s evolutionary perspective), or it provides a neural basis for the position taken by a particular theorist (e.g., it describes the neural and computational foundation for Chomsky’s nativist perspective).
2. The Pixel Parable: From Neurons to Narrative
Think of a digital screen: millions of pixels, each indifferent to the movies they display. Yet collectively, they create stories, emotions, and meaning. The brain operates similarly. Individual neurons, like pixels, lack awareness of their role in the whole. But through coordinated dynamics, they give rise to cognition—and ultimately, language. This is the short version of the Pixel Parable, available in the paper and here.
This dynamic, is formalized by the Pixel Parable Master Equation:
Here, conscious representation (Rep) emerges recursively from the integration of one’s own memories (M), sensory-motor data (S), and emotional states (E). Language, like a movie on a screen, is not stored in any single neuron but arises from the metastable attractors and Markov blankets that stabilize neural activity into coherent patterns, guided by the reinforcement of meaning-laden attractors (e.g., Hebbian learning). This is not a probabilistic guessing game (as Bayesian models suggest) or a static mental lexicon (as Fodor’s “Language of Thought” hypothesis implies), instead, language emerges as a stable but flexible attractor network, reinforced by sensorimotor input, recursive feedback loops, and social interaction.
Mathematically, this self-organization follows from a Recursive Lyapunov Minimization Principle:
Here, cognitive states evolve toward stable attractors (local minima in a Lyapunov potential V(Rep), while stochastic perturbations (η(t)) enable adaptive exploration. This equation captures how neural states stabilize over time, allowing linguistic structures to emerge not through symbolic encoding but through recursive energy minimization.
Language, in this view, is not something we “have”—it is something we do. It is a computational primitive that evolves, arising from:
The progressive stabilization of attractors, reinforcing patterns of meaning.
The formation of Markov blankets, dynamically regulating the boundaries between words, concepts, and internal representations.
Stability: Words and syntax form strong Markov blankets—deep attractors that resist noise (e.g., entrenched vocabulary).
Flexibility: Metaphor and creativity arise from weak Markov blankets—shallow attractors that permit transitions (e.g., novel phrases).
Belief updating through attractor shifts, ensuring that language remains adaptable rather than rigid.
For example, the grounding of the word “apple” is not symbolic but emerges from recursive sensorimotor integration:
This equation shows how the meaning of “apple” is dynamically shaped by past interactions (biting [SE], seeing[MS]) and emotional context (craving, nostalgia [ME]), stabilized by attractors yet adaptable to new experiences.
Thus, syntax, semantics, and linguistic comprehension are then not independent features of the mind, but instead emergent properties of thermodynamically regulated cognition. This unifies all previous linguistic theories, showing that both innate structures (Chomsky, Fodor) and learning mechanisms (Piaget, Krashen) are downstream effects of a deeper, more fundamental process. So let’s address it.
3. From Sensorimotor Primitives to Linguistic Aptitude
Language begins not with grammar, but with embodied computational primitives—neural processes that compress high-dimensional sensorimotor data into low-dimensional attractors. Our blood pressure, our body temperature, how deep we breathe, how spaced are our steps when we walk or how slow we can throw a rock, these are all spatiotemporal physics that our bodies unconsciously process every second. Computational primitives arise from the ongoing association of ever more complex sensory calculations with mnemonic symbols, emotions, valence, and (common+stable) environmental variables, which enables coherent associations, inference and extrapolations.
These primitives, such as rhythmic movement or spatial navigation, form the scaffold for abstract thought that eventually leads to lexical priming:
Here, neurocomputational states (C) recursively integrate sensorimotor patterns (P), memory (M), and error correction (Sac−Spr) [ac being a term for actual and pr a term for predicted feedback). Over time, these primitives are repurposed for language, through the use of symbols, more complex sounds and increasingly sophisticated gestures:
Syntax emerges from hierarchical attractor transitions (e.g., motor sequences → sentence structure).
Semantics arises from cross-modal mappings (e.g., “grasping” an idea mirrors physical grasping, also known as ‘action words’).
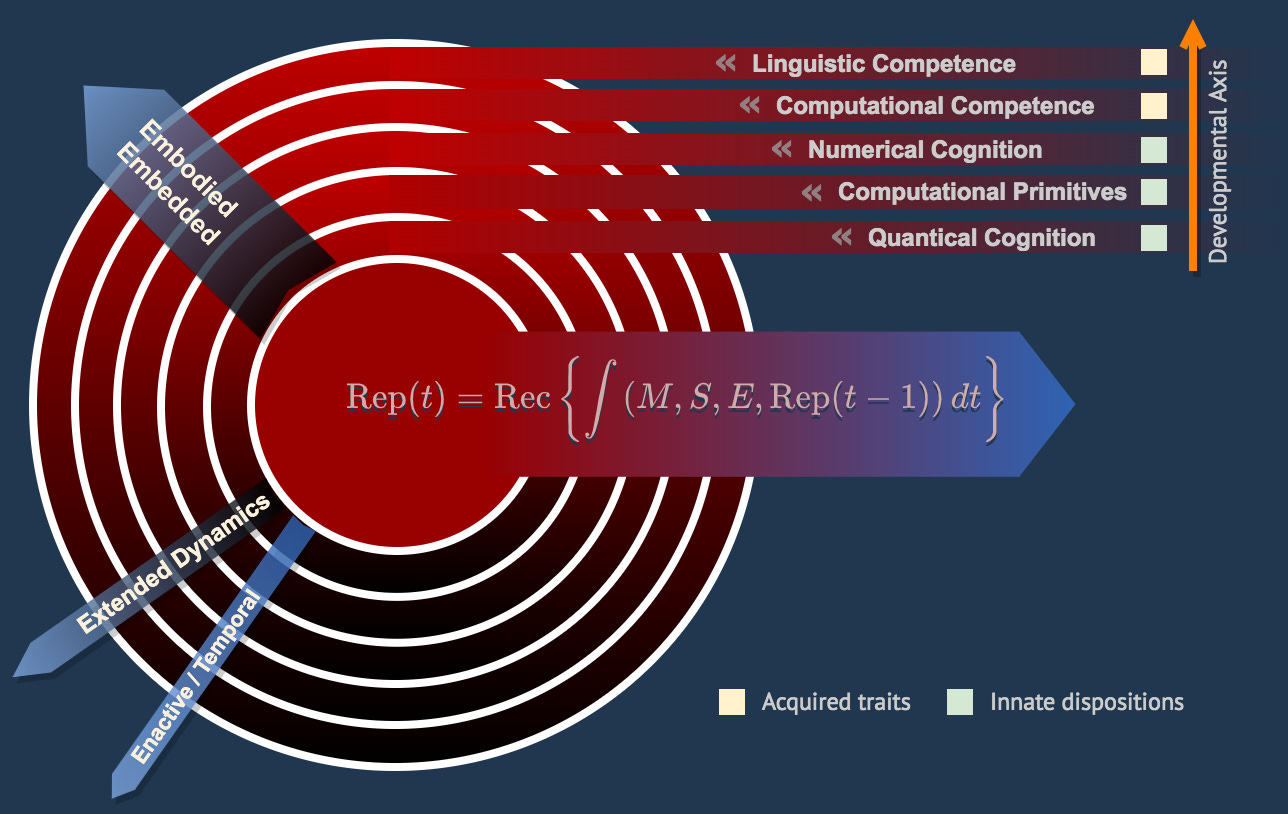
4. Redefining “Knowing” a Language
Traditional theories treat language as a static code. This framework reimagines it as a continuously evolving metabolic process:
Metabolic constraints (E) force the brain to balance energy expenditure with computational demands (i.e., Almor’s Informational Load Hypothesis and the Cognitive Load Theory). Language is then “learned” not by storing rules, but by refining attractors through error-driven recursion:
Here, linguistic representations (L) adapt to sensory feedback (λ⋅(Lac−Lpr)) while minimizing energy costs. To “know” a language is to inhabit a Lyapunov landscape where words, grammar, and meaning are transient equilibria—always stabilizing, always evolving.
In other words, this framework does not discard past theories—it subsumes them.
Chomsky’s Universal Grammar: Innate/mentalist structure arises from attractor landscapes shaped by evolutionary constraints.
Piaget’s Constructivism: Sensorimotor experience directly molds neural attractors.
Locke’s Tabula Rasa: The “blank slate” is a starting attractor configuration, refined by the 4E’s cognitive interaction.
Here, language is not a code to crack, it is a capability of our bodies to make use of multiple sensory data (4E, energy, entropy) and neural capabilities (representation, recursion, networks, attractors) just like it is a capability of our brains to fuse the visual input of two eyes as one single stream of coherent imagery: our brains use symbols, senses and meaning to convey thought through the use of symbolic language, sounds and signs.
In this sense, acquiring a first language (L1) is a default behavior akin to how learning to ambulate is also default, given our bodies limitations (e.g., a bird learns to fly and to chirp, humans learn to walk and to make complex sounds). Acquiring a second language (L2) is then akin to an “extra” step to our sensori-motor competences; for example, after learning to walk, a human can learn to parkour, which takes “extra” steps to reassign possibilities, commonalities, extrapolations (from an embodied and embedded perspective), same as acquiring L2 requires a person to reassign meaning to new sounds, gestures, etc., which is harder than L1, same as it is harder to parkour if compared to walk.
5. The Good, the Bad and the Ugly on AI vs this Framework
This theory offers a fundamental rethinking on how language emerges—one that could lead to AI systems with real understanding, adaptability, and efficiency. However, it faces serious adoption barriers, especially given that LLMs are already extremely effective despite lacking a mechanistic model of cognition. So lets explore the upsides and the downsides.
The Good: What this Framework Can Add to ML & AI
Current LLMs rely purely on statistical token prediction, with no underlying computational model for how meaning is structured. This framework could lead to AI models that form concepts more naturally rather than just optimizing for next-word probabilities.
LLMs require massive datasets and compute resources because they lack a self-organizing principle like the Recursive Lyapunov Minimization. This framework suggests a more efficient way to acquire language, where representations emerge through self-stabilizing attractors rather than brute-force parameter tuning.
Current models cannot “think” in a structured way beyond statistical associations. My narrative on Markov blanket-driven conceptual organization offers a blueprint for AI systems that could dynamically form and dissolve meaning structures, adapting language representations fluidly, instead of memorizing massive datasets.
By linking language to recursive self-organization and energy constraints, this framework could lead to AI that integrates real-world interactions with linguistic development, making them more human-like in comprehension.
The Bad: Challenges & Limitations
GPT-style architectures perform astonishingly well using just token prediction, transformers, and scale. While this theory is conceptually superior, it must demonstrate practical advantages over current models.
Neural networks today do not explicitly model attractors, Markov blankets, or energy minimization—they optimize for gradients and probability distributions. To use this framework, ML researchers would need to rethink architectures beyond transformers, which is a significant technical hurdle.
This framework is inherently physics-based, meaning it might not be optimal for classical GPUs/TPUs that operate on static matrix multiplications. Would AI hardware require dynamical system interpreters, new compression models, refactoring?
The Ugly: Where this Theory & LLMs Collide
This framework proposes a true mechanistic foundation for linguistic cognition. LLMs, on the other hand, are not cognitive systems, yet they mimic intelligent behavior well enough that people assume they “think”. If perception = reality, does AI need a physics-based model of language at all?
This theory predicts that language must be stabilized by energy constraints and recursive belief updating—yet, LLMs create fluent, seemingly deep text with no structured belief system at all. If today’s AI is “good enough” for language tasks, will researchers bother moving toward physically grounded cognition?
Big tech companies are investing in scaling existing transformer models, not fundamentally new architectures. Even if this framework is theoretically superior, it must demonstrate empirical gains in efficiency, explainability, or performance for AI labs to take the risk of transitioning, huge uncertainty here.
So if these challenges are met, this framework could improve AI—not by replacing LLMs, but by augmenting them with a deeper foundation for true linguistic intelligence and cognition.
6. Bridging Frameworks: From Transformers to Thermodynamic Cognition
To depict how this theory contrasts with—and potentially auguments—current AI architectures like transformers, one may first dissect their core mechanisms and then map them to this framework’s principles.
Transformers process language through scaled dot-product attention, which identifies relationships between tokens (words or subwords) in a sequence. At a high level, its attention mechanism can be defined as:
, and
Queries (Q), keys (K), and values (V) are linear transformations of input embeddings. The attention mechanism computes attention scores by taking the dot product between the query (Q) and the key (K) vectors, scaling it by √dk (where dk is the dimensionality of the key vectors), and then applying the softmax function to obtain normalized attention weights. Here, the first equation calculates the output of the attention mechanism, which is a weighted sum of the value vectors (V), where the weights are determined by the similarity between queries and keys, and the second computes the probability distribution over possible next tokens (or words) based on the attention weights, which is crucial for tasks like language modeling and text generation.
The model learns to attend to relevant tokens by optimizing attention weights during training and in the case of autoregressive models, it calculates the next token’s probability distribution using the attention mechanism. While effective, this process:
Relies on statistical correlations in text data (e.g., “apple” co-occurs with “pie”).
Lacks embodied grounding (e.g., no sensorimotor experience of biting an apple).
Operates as a static function after training, unable to adapt dynamically.
This framework treats language as a dynamical system governed by a Recursive Lyapunov Minimization Principle (equation 2.2), metabolic constraints (equation 4.1) and a reality threshold, that in the original paper is defined as:
This mechanism distinguishes grounded experience (e.g., seeing an apple) from imagination (e.g., picturing one), which could reduce hallucinations by tethering symbols to sensorimotor input analogues.
While Transformers excel at generating fluent text, they suffer from:
Hallucinations: Producing plausible-but-false statements (e.g., “apples are blue”), as they lack embodied grounding.
Static Knowledge: Inability to update beliefs post-training (e.g., learning a new word).
Energy Inefficiency: Massive compute costs.
This framework addresses these by:
Grounding Symbols: Words map to sensorimotor attractors (e.g., “apple” ≈ taste/texture/memory integration).
Dynamic Adaptation: Continuous error correction (equation below) enables lifelong learning.
Energy Efficiency: Metabolic constraints enforce parsimony, mimicking the brain’s frugality (equation 4.2).
While far from being a LLM engineer, I think it would be fair to suggest hybrid architectures to bring these two worlds together, so in theory, we could:
Guide attention with Lyapunov gradients (−∇V):
\(\text{Attention}(Q, K, V) = \text{softmax} \left( \frac{-\nabla V(Q,K^T)}{\sqrt{d_k}} \right) V\)Incorporate error-driven refinement into transformer blocks as recursive predictive layers:
\(Block_\text{t+1}=Block_t+λ⋅(S_\text{ac}−S_\text{pr})\)Where Sac (actual sensor input) and Spr (predicted input) drive updates, mimicking biological predictive coding.
Add a metabolic cost term to the loss function:
\(L_{\text{total}} = L_{\text{task}} + \alpha \cdot E(\text{Rep})\)To penalize energy-expensive representations, steering models toward efficient attractors.
While today’s LLMs are definitely “good enough” for many tasks, they remain brittle, opaque, and energy-hungry. This framework offers a path to AI systems that:
Understand language through embodied grounding.
Adapt continuously like biological brains.
Explain decisions via attractor dynamics.
For AI labs, the incentive is clear: systems built on these principles could achieve superior efficiency, robustness, and explainability—critical for high-stakes applications like healthcare, robotics, or autonomous systems. While transitioning from transformers is risky, the long-term payoff—a machine that doesn’t just generate language but understands it—could one day redefine AI’s role in society, and this framework offers a blueprint for machines that think less like calculators and more like living systems. Although implementing such a model would require rethinking existing architectures, the potential gains in efficiency, interpretability, and cognitive depth make it a compelling direction for further research and development in AI, either merely as a more “human” distillation model for LLMs or as a true embodied cognitive platform for robotics.
While language is a hallmark of human intelligence, it is far from the only one. This framework, with its emphasis on embodied cognition and dynamic learning, opens up possibilities for AI to excel in other cognitive domains. Think of AI that can not only understand language but also understand complex problems, art, or even empathize with humans. The potential is vast, but so are the challenges. We must explore how the numerous aspects of intelligence can be integrated into AI systems, to measure the impacts of moving from AI that simulates intelligence to AI that genuinely experiences it, and this brings challenges from the future to the present: If AI attains embodied sentience, what rights do we afford it? How do we ensure alignment with human values? Is the world truly prepared for this leap?
So at this point, the future of AI may well hinge on those who dare to build it in our image, and this framework provides A path to do this.
Some will undoubtedly ask: Could this be yet another route to AGI? Realistically, compared to models that rely solely on shallow statistical correlations, this framework offers a genuine alternative. However, the AI industry, deeply invested in transformer-based architectures supported by vast computational resources and massive datasets, will likely see the shift to this model as daunting. This framework demands a fundamental shift in how we think about intelligence, research culture, and business KPIs. While the desire for AGI is palpable, this kind of transformation requires extensive validation to prove its merit, and that’s a conversation for another time.
